JAVA日志专辑
欢迎你来读这篇博客,这篇博客主要是关于Java日志的分享。
其中包括了关于我的经验和收集的知识分享。
序言
Java日志是 Java 开发中非常重要的组件,它可以帮助我们快速定位问题,也可以帮助我们快速定位问题。
先来点直接的。
推荐使用 log 日志输出调试信息而不要使用 System.out.println()方法,主要是因为 println()使用了同步锁,会影响程序的并发性能和系统的吞吐量。
日志的分类
日志级别
- 错误级别:ERROR
- 警告级别:WARN
- 信息级别:INFO
- 调试级别:DEBUG
- 跟踪级别:TRACE
强制标准:打印日志判断级别
目的是支持动态修改日志级别,以及环境区分。dev/test 环境可能会打印大量 info 用于开发测试调试,线上并不需要这些日志。或者线上出问题了,动态修改日志级别,再去打印此类日志。
线上分析工具,Arthas支持动态修改日志级别,以及更多操作。Arthas
1 | |
日志类型
- 系统日志:系统日志是指系统运行过程中的日志,比如系统启动,系统关闭等。
- 应用日志:应用日志是指应用运行过程中的日志,比如用户登录,用户操作等。
- 访问日志:访问日志是指用户访问系统的日志,比如用户访问的页面,用户访问的接口等。
好的日志习惯
- 日志格式统一
- 日志文件大小拆分策略
- 不打无用日志
- 关键信息提到最前
- 敏感信息和日期
- 用好 debug 级别
- 用好切面日志
优化日志的输出格式
官网对这几类模式的说明中反复强调了会影响性能。如果使用了如下属性输出,将极大的损耗性能:
比如 log4j 官网
1 | |
Java 日志框架总览
理解日志库需要从下面三个角度去理解:
- 最重要的一点是 区分日志系统和日志门面;
- 其次是日志库的使用, 包含配置与 API 使用;配置侧重于日志系统的配置,API 使用侧重于日志门面;
- 最后是选型,改造和最佳实践等
日志的艺术
理解日志并不是一件容易的事,开发人员在编写代码之时往往会纠结在某处打印的日志是不是有意义的,而 SRE 在面对缺少日志的生产问题时往往一筹莫展,Ops
在对面海量日志时往往需要花费更多的精力来维护,而项目的实际管理者在面对毫无实际业务价值的日志时,往往不想花费太多的人力和财力去管理它。
因此,在开发应用程序时遵循良好的实践,在收集管理日志时选用成熟的方案,往往能让这些矛盾得以缓解,这也就有了这一篇的分享。
矛盾的开始
首先介绍的是为什么需要记录日志,日志的作用。其实关于日志的作用无需介绍太多,因为大多数的开发人员在调试代码问题时,解决不同环境的
Bug
时都有很明确的感受以及强烈的需求。日志作为调试的助手,生产环境的救星。笔者只见过嫌弃日志打的太少的,几乎没有见过嫌弃日志打的太多的开发和运维人员。通过查询日志的方式来确定代码的分支走向,API 是否请求正确,核心业务的数据是否正确,是否有错误的堆栈信息,这些都构成开发和运维人员判断代码和生产问题的第一手段。笔者难以想象如果一个复杂庞大的系统没有记录任何日志,该如何排查生产环境的
Bug。
如果有如此强烈的需求,那每一行代码都打日志来记录上下文不就行了吗?这样无论什么环境有什么代码有问题,通过搜索日志都可以排查出来。理论上这样确实可行,但是有一些问题目前无法解决,一是日志存储量的问题,常见的中大型系统日志大概在
TB 级,超大型系统的日志大概在 PB 级,根据 Cloudflare 提供的数据,它每秒大概处理 4 千万的请求,这对于存储的费用来讲是一个巨大的挑战。二是搜索的性能下降,像
Elasticsearch 数据库这类常见的日志存储方案,海量的日志会导致其所维护的映射关系爆炸式增长,即使划分不同的 Index,分布式管理不同的
ElasticSearch 集群,也很难做到搜索性能不随数据量的增加而下降。三是海量日志的生成会在峰期时拖慢系统性能,增大出故障的风险。
所以综上可以得出最简单的结论,即日志既不能打印太多导致存储和管理日志太难,也不应该因为打印太少导致运维人员无法排查问题,这听起来自相矛盾,但这就是关于日志的艺术!
- 场景一
- 某工程师在调查生产环境中某个创建资源的 API 性能较低问题时,发现是由于该 API 在保存资源前做了写 INFO
级别的日志,将资源对象都写到日志中,由于资源的对象属性很多,所以导致在业务峰期时,代码打印出海量日志,耗尽 Buffer 区内存,从而拖慢主线程,造成服务性能整体下降。因此该工程师将该业务日志打印操作删除,以降低生产环境磁盘
IO 损耗,解决性能问题。 - 但是某天由于修改了该 API 服务调用链路上的某服务代码,导致该 API 创建出来的对象有错误,并且由于缺少了生产环境保存该资源时的日志,无法排查出是
API 的请求参数有问题,还是后续的计算逻辑有问题。这时我们只能重新修改日志级别,重新构建发布上线吗?
- 某工程师在调查生产环境中某个创建资源的 API 性能较低问题时,发现是由于该 API 在保存资源前做了写 INFO
- 场景二
- 假设将生产环境的日志设置为 ERROR 级别。某一时刻,依赖的下游服务故障,导致请求大量超时。又由于在业务峰期 QPS
非常高的时期,短时间内集中产生大量的错误日志,导致磁盘 IO 急剧提高,耗费大量 CPU,进而导致整个服务瘫痪。我们应该如何处理?
- 假设将生产环境的日志设置为 ERROR 级别。某一时刻,依赖的下游服务故障,导致请求大量超时。又由于在业务峰期 QPS
- 场景三
- 某工程师在排查生产问题时,发现 INFO 级别的日志还无法满足排查 Root Cause,有一个 DEBUG 日志级别的日志是他需要的,但是生产环境只有
INFO 级别,这时只能修改级别然后重新启动服务吗?
- 某工程师在排查生产问题时,发现 INFO 级别的日志还无法满足排查 Root Cause,有一个 DEBUG 日志级别的日志是他需要的,但是生产环境只有
日志级别规范与动态调整
解决以上问题的方法,一是需要我们在项目中,明确日志级别的规范,不为了调试方便和减少存储随意使用日志级别。二是给日志级别加上动态调整的功能。也就是需要解决线上问题时,调低线上日志输出级别,获取全面的 Debug 日志,帮助工程师提高定位问题的效率。在生产日志海量增加拖慢服务性能时,调高线上日志输出级别,减少日志的生成,缓解磁盘
IO 压力和提高服务性能。
以下是对于日志级别给出的建议:
- TRACE:应该在开发期间使用它来追踪错误,但永远不要提交到版本控制系统(VCS)中。
- DEBUG:记录程序中发生的任何事情。主要在调试期间使用,建议在进入生产阶段之前缩减调试语句的数量,只留下最有意义的条目,并可以在故障排除期间激活。
- INFO:记录所有由用户驱动的事件或特定于系统的操作(例如定期计划操作)。
- WARN:此级别记录所有可能成为错误的事件。例如,如果一个数据库调用花费的时间超过预定义的时间,或者如果内存缓存接近容量。这将允许适当的自动警报,并在故障排除期间允许更好地了解系统在故障之前的行为方式。
- ERROR:在此级别记录每个错误条件。这可以是返回错误或内部错误条件的 API 调用。
- FATAL:代表整个服务已经无法工作。请非常节制地使用这个级别。通常此级别记录表示程序的结束。
记录日志
- 什么时候记录日志
- 什么时候记录日志并没有标准规范,需要开发人员根据业务和代码来自行判断,除了常规的记录事件,例如进行了哪些操作、发生了与预期不符的情况、运行期间出现未能处理的异常或警告、定期自动执行的任务外。笔者还建议在以下场景加上日志:
- 在调用第三方系统时,将调用 API 的 URL 带上 Request/Response Body
和异常都记录到日志。原因是当发生故障时,能够有明确且清晰的的日志报告说明故障原因,减少不同系统服务运维人员或者不同公司之间的责任界定,以更顺畅的方式推动问题的解决。 - 在重要核心业务的关键代码和分支加上日志,例如 if-then-else
语句,它可以帮助开发人员了解程序是否根据其当前状态遍历了预期路径。并且由于核心业务的数据普遍难以手动复现,了解代码分支的走向至关重要。 - 核心业务的审计日志,如果某业务和法律或合同具有关联性,给对应的操作加上审计日志是非常有必要的。并且存储日志要求强一致性数据库。
- 应用服务启动时输出配置信息。初始化配置的逻辑一般只会执行一次,不便于诊断时复现,所以应该输出到日志中。
日志属性
除了在日志常规需要打印的 log level,timestamp,message,exception 和 stack trace 外,排查问题往往还需要其它的字段来帮助定位和查找
Root Cause,常见的额外字段有以下几种:
- trace id 即服务链路追踪的唯一 ID。在请求进入到系统 7 层网关时,即在 HTTP header 中加上对应请求整个生命周期唯一的 trace
id,并随着该请求调用一直携带。当请求链路过长,开发人员难以找到完整的请求日志时,trace id 有助于反向查找完整日志。 - span id 即表示 trac id 生命周期中拆分的单个操作。例如当请求到达每个服务后,服务都会为请求生成 spanid,第一个 spanid 称之为
root span,而随请求一起从上游传过来的 spanid 会被记录成 pspanid (parent-spanid)。当前服务生成的 spanid
随着请求一起再传到下游服务时,这个 spanid 又会被下游服务当做 pspanid 记录。由此 span id 有助于当服务调用复杂时还原出整个请求的调用链路视图。 - user id 即用户的唯一 ID。确保当用户上报 Issue 或者提交 TIcket 的时候,可以根据当前用户的唯一 ID 直接查询对应错误日志,减少干扰项,缩短排查周期。
- tenant_id 这是租户 ID(如果存在)。对多租户系统非常有帮助
- request uri 即当前微服务请求 URI (用户一个业务操作可能对应着多个服务不同的 request uri),当某业务出现问题时,通过该业务对应入口的
request uri 往往能很快拿到 trac id,再通过 trac id 去查找对应请求的日志往往能很快解决问题。 - application name 即当前微服务名称。有助于识别哪个服务生成了此日志,也有助于通过 application name 过滤日志,查询服务整体故障。
- pod name 即当前请求所在的 k8s 资源 Pod 名称(如果存在)。目前大多数微服务使用 k8s 来完成容器编排,打印 pod name 有助于当某个
pod 故障时,重启或者 Kill Pod。 - host name 即当前请求所在的机器名称。即使使用 k8s 托管微服务,也会出现由于 k8s 集群所在的某台机器出现磁盘或者网络故障时,服务无法正常工作的情况,打印
host name 有助于排查问题最后一公里,即由于机器硬件问题导致故障。
日志 Sec
日志需要保证日志框架的安全和敏感信息处理。框架安全指的是使用成熟的,经过大量生产环境验证的日志框架库,而非自己造轮子。敏感信息处理是大部分公司的生命线,请牢记日志的安全性和合规性要求:
- 不要泄露敏感的个人身份信息 (PII)。
- 不要泄露加密密钥或秘密。
- 确保公司的隐私政策涵盖日志数据。
- 确保日志提供商满足合规性需求。
- 确保满足数据存储时间要求。
bad smell
- 使用中文或者非英文打印日志。
- 英文表示日志将以 ASCII 字符记录。这一点特别重要,因为像中文经过一系列处理后,它可能因为字符集或者编码集最终无法正确呈现。
- 英文自带分词效果,像使用 ElasticSearch 这类倒排索引存储引擎存储日志,中文日志不仅需要添加专门的分词器,并且存储和查询效果不如英文。
- 没有上下文的日志。类似直接打印 Transaction failed 或者 User operation succeeds
这类日志。因为在写代码时通过代码上下文能够理解日志消息,但是当阅读日志本身时,这个上下文不存在,这些消息可能无法理解。 - 将打印日志的操作放在循环当中。除非特定需求,否则打印出来的日志不仅难以阅读和查找,还会耗费大量存储资源。
- 引用慢操作数据,如果当前上下文中没有打印日志需要的数据,需要调用远程服务或者从数据库获取,又或者通过大量计算,那应该先考虑这项信息放到日志中是不是必要且恰当的。
日志 visible
最近十年因为微服务和云原生的相继崛起,收集存储和分析日志领域发生了重大的变化。早期我们无需进行日志的收集,当时将单体服务的所有日志存储在文件当中,使用
tail、grep、awk 来从日志中挖掘信息。但是在系统日益复杂的今天,这种方式已经无法满足我们的需求。为了应对日益复杂的日志管理需求,开源社区和工业界也发展出一些列的方案,例如最为流行的
Elastic Stack 开源解决方案,云厂商提供的一站式解决方案像 AWS DataDog 和 Azure Dynatrace。
无论使用哪种方案,日志管理都已经不再是一个简单的话题。在我们有明确感知的打印日志和查询分析日志之间,还包含着对日志进行收集、缓冲、聚合、加工、索引、存储等若干个步骤,并且每一步都蕴含着艰难曲折。
日志 collection
最早我们使用 Elastic Stack 中的 Logstash 来进行日志的收集和加工。系统中不同的服务通过使用 tcp/udp 的协议,主动发送请求将日志推送到
Logstash 中,接着 Logstash 将日志进行转换加工(数据结构化)和输出。这种模式维持了很长一段时间,但是它也有比较严重的缺陷,那就是
Logstash 与它的插件是基于 JRuby 编写的,要跑在单独的 Java 虚拟机进程上,默认的堆大小就到了
1GB。如果需要部署成千上万个日志收集器,那么这种方案就显得太过沉重。所以后来 Elastic.co 公司使用 Golang
重写了一个功能较少,却更轻量高效的日志收集器 Filebeat 才缓解了这一矛盾。
除此之外 Fluentd 通常是配合 Kubernetes 时的首选开源日志收集器。它是 Kubernetes 原生的,可以使用 DaemonSet 的方式部署与
Kubernetes 无缝集成。它允许从不同的地方像 Kubernetes 集群、MySQL、Apache2 等收集日志,并解析发送到所需位置如
Elasticsearch、Amazon S3 等。Fluentd 用 Ruby 编写的,在低容量下运行良好,但当需要增加节点和应用程序的数量时,也会有会性能问题。
最后在日志收集时,有可能会因为业务峰期生成海量日志,影响服务稳定性和造成日志丢失。在这种情况下,我们还需要在 Logstash
或者存储日志数据库前加上一道缓冲层。在较小规模的系统中 Redis streams 是一个较好的选择,如果面对的规模更大的数据,那么 Kafka
集群或者云厂商提供的消息队列解决方案将是不二之选。
日志 struct
在收集完日志后,我们还需要进行结构化的处理。因为日志是非结构化数据,一行日志中通常会包含多项信息,如果不做处理,那只能以全文检索的原始方式去使用日志,这样既不利于统计对比,也不利于条件过滤。像下面这一行是
Nginx 服务器的 Access Log。
1 | |
尽管我们已经习惯了默认的 Nginx 格式,但上面的示例仍然难以阅读和处理。我们可以通过 Logstash 或者其它工具将它转换成结构化的数据,例如
JSON 格式。
1 | |
经过结构化后,例如像 ElasticSearch 这类倒排索引数据库可以针对不同的数据项建立索引,进行查询统计、聚合等操作。
除此之外还有一种工业界的做法像 Splunk 推荐将字段变为 key-value 对的形式放在同一个大的规范日志行中(logfmt),如将 Nginx
日志作为规范日志行将变成如下这样:
1 | |
这类数据经过 Splunk 存储后,可以通过使用内置的查询语言进行检索,像使用 method=get status=500 查询所有返回 500 响应的 GET
方法。使用 method=get method=get status=500 earliest=-7d | timechart count 查询语句得到过去 7 天返回 500 响应的 GET
方法总数量和图表。
日志的存储与查询
经过日志的数据结构化后,可以将数据存入数据库中并进行查询分析。在选择使用什么方案来存储和分析之前,我们先来看看日志数据的特点。
- 日志是写入密集型的,超过 99% 的日志写入后不会被查询使用。
- 日志是标准的时间流数据,需要顺序写入,存储到数据库后,不会再进行修改变动。
- 日志是具有时效性的,一般只需要最近一段时间的日志来查询分析或者排查故障,一段时间以后会被保留策略清除或者归档。
- 日志是半结构化的,尽管我们将所有应用服务的日志都进行结构化,还是还包含系统日志,网络日志等日志,它们字段各不相同。
- 查询日志依赖全文检索和即席查询(Ad-hoc search)。
- 查询日志不要求日志具有强时效性,但是也无法接受按小时甚至按天的延时。
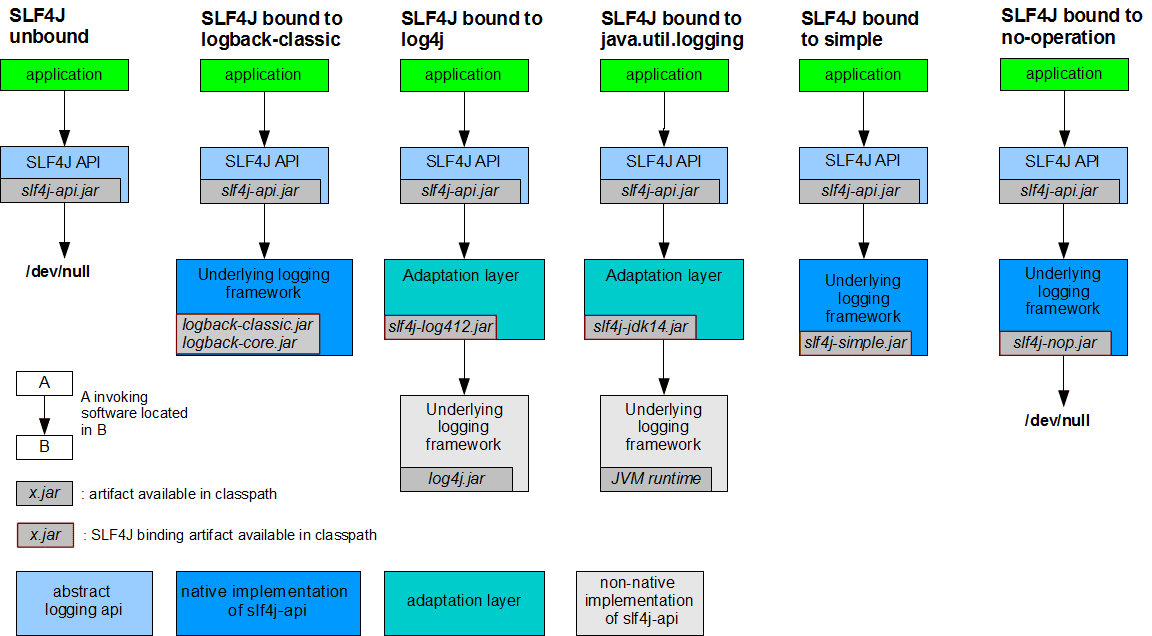
日志框架-日志系统
目前 SpringBoot 目前支持 4 种类型的日志,分别是 JDK 内置的 Log(JavaLoggingSystem)以及 Log4j(Log4JLoggingSystem)、Log4j2(
Log4J2LoggingSystem)以及 Logback(LogbackLoggingSystem).
LoggingSystem 是个抽象类,内部有这几个方法:
- beforeInitialize 方法:日志系统初始化之前需要处理的事情。抽象方法,不同的日志架构进行不同的处理
- initialize 方法:初始化日志系统。默认不进行任何处理,需子类进行初始化工作
- cleanUp 方法:日志系统的清除工作。默认不进行任何处理,需子类进行清除工作
- getShutdownHandler 方法:返回一个 Runnable 用于当 jvm 退出的时候处理日志系统关闭后需要进行的操作,默认返回 null,也就是什么都不做
- setLogLevel 方法:抽象方法,用于设置对应 logger 的级别
SpringBoot 在启动时,会完成 LoggingSystem 的初始化,这部分代码是在 LoggingApplicationListener 中实现的
有了 LoggingSystem 以后,我们就可以通过他的 setLogLevel 方法来动态的修改日志级别。他帮我们屏蔽掉了底层的具体日志框架。
1 | |
java.util.logging (JUL)
JDK1.4 开始,通过 java.util.logging 提供日志功能。虽然是官方自带的 log lib,JUL 的使用确不广泛。
主要原因:JUL 从 JDK1.4 才开始加入(2002 年),当时各种第三方 log
lib 已经被广泛使用了 JUL 早期存在性能问题,到 JDK1.5 上才有了不错的进步,但现在和 Logback/Log4j2 相比还是有所不如 JUL 的功能不如 Logback/Log4j2 等完善,比如 Output
Handler 就没有 Logback/Log4j2 的丰富,有时候需要自己来继承定制,又比如默认没有从 ClassPath 里加载配置文件的功能
Log4j
Log4j 是 apache 的一个开源项目,创始人 Ceki Gulcu。
Log4j 应该说是 Java 领域资格最老,应用最广的日志工具。Log4j
是高度可配置的,并可通过在运行时的外部文件配置。它根据记录的优先级别,并提供机制,以指示记录信息到许多的目的地,诸如:数据库,文件,控制台,UNIX
系统日志等。Log4j 中有三个主要组成部分:
- loggers - 负责捕获记录信息。
- appenders - 负责发布日志信息,以不同的首选目的地。
- layouts - 负责格式化不同风格的日志信息。
- 官网地址:http://logging.apache.org/log4j/2.x/
Log4j 的短板在于性能,在 Logback 和 Log4j2 出来之后,Log4j 的使用也减少了。
Logback
Logback 是由 log4j 创始人 Ceki Gulcu 设计的又一个开源日志组件,是作为 Log4j 的继承者来开发的,提供了性能更好的实现,异步
logger,Filter 等更多的特性。
logback 当前分成三个模块:logback-core、logback-classic 和 logback-access。
- logback-core - 是其它两个模块的基础模块。
- logback-classic - 是 log4j 的一个 改良版本。此外 logback-classic 完整实现 SLF4J API 使你可以很方便地更换成其它日志系统如
log4j 或 JDK14 Logging。 - logback-access - 访问模块与 Servlet 容器集成提供通过 Http 来访问日志的功能。
官网地址: http://logback.qos.ch/
Log4j2
维护 Log4j 的人为了性能又搞出了 Log4j2。Log4j2 和 Log4j1.x 并不兼容,设计上很大程度上模仿了
SLF4J/Logback,性能上也获得了很大的提升。Log4j2 也做了 Facade/Implementation 分离的设计,分成了 log4j-api 和 log4j-core。
官网地址: http://logging.apache.org/log4j/2.x/
Log4j vs Logback vs Log4j2
从性能上 Log4J2 要强,但从生态上 Logback+SLF4J 优先
为什么禁止工程师直接使用日志系统中的 API
- 使用门面日志系统,解耦。
- 门面模式针对日志系统做了优化性的封装
门面型日志框架
最常见的门面模式/外观模式应用场景,面试被问设计模式再也不害怕啦!
JCL
Jakarta Commons-logging
他是 apache 开源的对 jdk log 进行封装的 log 组件,是一套 Java 日志接口。他可以配合 log4j.不需要强依赖他们。松耦合的状态。
- 首先去找配置文件 commons-logging.properties,找不到的情况那么默认 Log 的实现类。
- 找到是否有其他的组件库比如 log4j
- 找不到用 jdk 的原生
- 找不到结合 commons-logging 自己提供这个日志实现类
官网地址: http://commons.apache.org/proper/commons-logging/
Sel4j
Simple Logging Facade for Java,缩写 Slf4j。是一套简易 Java 日志门面,本身并无日志的实现。
已经有 log 组件了,为什么还要再开发一套新的组件?
- log 打印的时候支持通配符
- 封装的比较完整
- 速度比较快
- 不会影响 gc
- 支持异步不影响业务设计的比较清晰
官网地址: http://www.slf4j.org/
细节差异:
- Log4j 提供 TRACE, DEBUG, INFO, WARN, ERROR 及 FATAL 六种纪录等级,但是 SLF4J 认为 ERROR 与 FATAL 并没有实质上的差别,所以拿掉了
FATAL 等级,只剩下其他五种。 - 大部分人在程序里面会去写 logger.error(exception),其实这个时候 Log4j 会去把这个 exception tostring。真正的写法应该是 logger(
message.exception);而 SLF4J 就不会使得程序员犯这个错误。 - Log4j 间接的在鼓励程序员使用 string 相加的写法(这种写法是有性能问题的),而 SLF4J 就不会有这个问题
,你可以使用 logger.error(“{} is+serviceid”,serviceid); - SLF4J 只支持 MDC,不支持 NDC。
选型
日志打点 API 绑定实现
slf4j-api 和 log4j-api 都是接口,不提供具体实现,理论上基于这两种 api 输出的日志可以绑定到很多的日志实现上。slf4j 和 log4j2 也确实提供了很多的绑定器。简单列举几种可能的绑定链:
- slf4j → logback
- slf4j → slf4j-log4j12 → log4j
- slf4j → log4j-slf4j-impl → log4j2
- slf4j → slf4j-jdk14 → jul
- slf4j → slf4j-jcl → jcl
- jcl → jul
- jcl → log4j
- log4j2-api → log4j2-cor
- log4j2-api → log4j-to-slf4j → slf4j
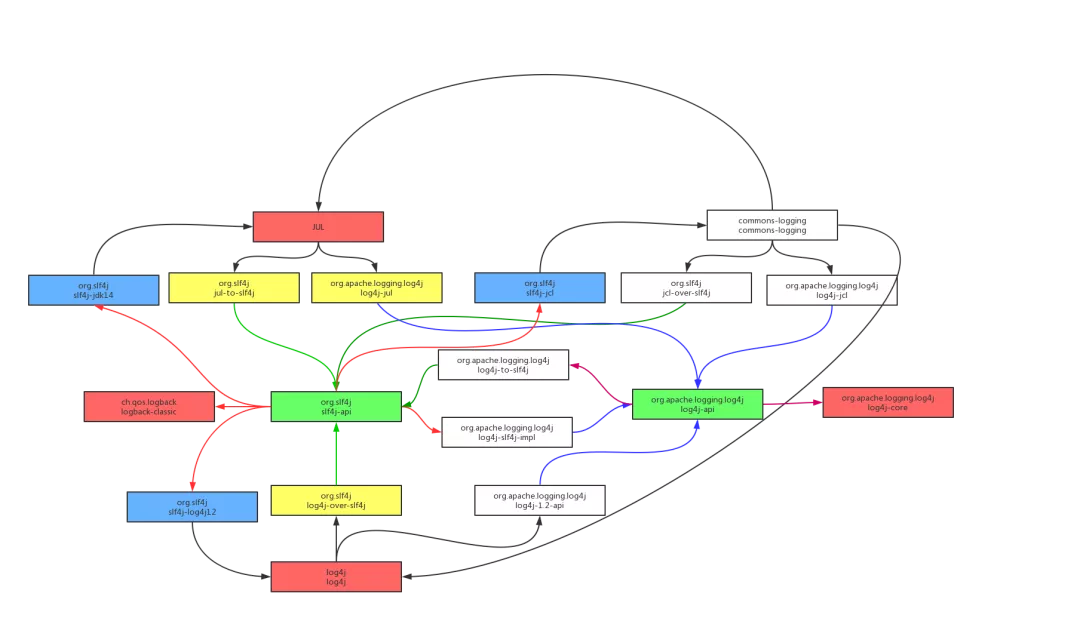
对 Java 日志组件选型的建议
slf4j 已经成为了 Java 日志组件的明星选手,可以完美替代 JCL,使用 JCL 桥接库也能完美兼容一切使用 JCL 作为日志门面的类库,现在的新系统已经没有不使用 slf4j 作为日志 API 的理由了。日志记录服务方面,log4j 在功能上输于 logback 和 log4j2,在性能方面 log4j2 则全面超越 log4j 和 logback。所以新系统应该在 logback 和 log4j2 中做出选择,对于性能有很高要求的系统,应优先考虑 log4j2
对日志架构使用比较好的实践
总是使用 Log Facade,而不是具体 Log Implementation
正如之前所说的,使用 Log Facade 可以方便的切换具体的日志实现。而且,如果依赖多个项目,使用了不同的 Log Facade,还可以方便的通过
Adapter 转接到同一个实现上。如果依赖项目使用了多个不同的日志实现,就麻烦的多了。
具体来说,现在推荐使用 Log4j-API 或者 SLF4j,不推荐继续使用 JCL。
只添加一个 Log Implementation 依赖
毫无疑问,项目中应该只使用一个具体的 Log Implementation,建议使用 Logback 或者 Log4j2。如果有依赖的项目中,使用的 Log
Facade 不支持直接使用当前的 Log Implementation,就添加合适的桥接器依赖。
具体的日志实现依赖应该设置为 optional 和使用 runtime scope
在项目中,Log Implementation 的依赖强烈建议设置为 runtime scope,并且设置为 optional。例如项目中使用了 SLF4J 作为 Log
Facade,然后想使用 Log4j2 作为 Implementation,那么使用 maven 添加依赖的时候这样设置:
1 | |
设为 optional,依赖不会传递,这样如果你是个 lib 项目,然后别的项目使用了你这个 lib,不会被引入不想要的 Log Implementation 依赖;
Scope 设置为 runtime,是为了防止开发人员在项目中直接使用 Log Implementation 中的类,而不适用 Log Facade 中的类。
如果有必要, 排除依赖的第三方库中的 Log Impementation 依赖
这是很常见的一个问题,第三方库的开发者未必会把具体的日志实现或者桥接器的依赖设置为 optional,然后你的项目继承了这些依赖——具体的日志实现未必是你想使用的,比如他依赖了 Log4j,你想使用 Logback,这时就很尴尬。另外,如果不同的第三方依赖使用了不同的桥接器和 Log 实现,也极容易形成环。
这种情况下,推荐的处理方法,是使用 exclude 来排除所有的这些 Log 实现和桥接器的依赖,只保留第三方库里面对 Log Facade 的依赖。
比如阿里的 JStorm 就没有很好的处理这个问题,依赖 jstorm 会引入对 Logback 和 log4j-over-slf4j 的依赖,如果你想在自己的项目中使用 Log4j 或其他 Log 实现的话,就需要加上 excludes:
1 | |
避免为不会输出的 log 付出代价
Log 库都可以灵活的设置输出界别,所以每一条程序中的 log,都是有可能不会被输出的。这时候要注意不要额外的付出代价。
先看两个有问题的写法:
1 | |
第一条是直接做了字符串拼接,所以即使日志级别高于 debug 也会做一个字符串连接操作;
第二条虽然用了 SLF4J/Log4j2 中的懒求值方式来避免不必要的字符串拼接开销,但是 toJson()这个函数却是都会被调用并且开销更大。
推荐的写法如下:
1 | |
日志格式中最好不要使用行号,函数名等字段
原因是,为了获取语句所在的函数名,或者行号,log 库的实现都是获取当前的 stacktrace,然后分析取出这些信息,而获取 stacktrace 的代价是很昂贵的。如果有很多的日志输出,就会占用大量的 CPU。在没有特殊需要的情况下,建议不要在日志中输出这些这些字段。
最后, log 中不要输出稀奇古怪的字符!
部分开发人员为了方便看到自己的 log,会在 log 语句中加上醒目的前缀,比如:
1 | |
虽然对于自己来说是方便了,但是如果所有人都这样来做的话,那 log 输出就没法看了!正确的做法是使用 grep 来看只自己关心的日志。
java 日志模板 logback
1 | |
java 日志模板 log4j2
1 | |
配置文件详解
- 日志级别
- 机制:如果一条日志信息的级别大于等于配置文件的级别,就记录。
- trace:追踪,就是程序推进一下,可以写个 trace 输出
- debug:调试,一般作为最低级别,trace 基本不用。
- info:输出重要的信息,使用较多
- warn:警告,有些信息不是错误信息,但也要给程序员一些提示。
- error:错误信息。用的也很多。
- fatal:致命错误。
- 输出源
- CONSOLE(输出到控制台)
- FILE(输出到文件)
- 格式
- SimpleLayout:以简单的形式显示
- HTMLLayout:以 HTML 表格显示
- PatternLayout:自定义形式显示
PatternLayout 自定义日志布局:
1 | |
Log4j2 配置详解
根节点 Configuration 有两个属性:
status
monitorinterval
有两个子节点:Appenders
Loggers(表明可以定义多个 Appender 和 Logger).
status 用来指定 log4j 本身的打印日志的级别.
monitorinterval 用于指定 log4j 自动重新配置的监测间隔时间,单位是 s,最小是 5s.
Appenders 节点
常见的有三种子节点:Console、RollingFile、File
Console 节点用来定义输出到控制台的 Appender.
- name:指定 Appender 的名字.
- target:SYSTEM_OUT 或 SYSTEM_ERR,一般只设置默认:SYSTEM_OUT.
- PatternLayout:输出格式,不设置默认为:%m%n.
File 节点用来定义输出到指定位置的文件的 Appender.
- name:指定 Appender 的名字.
- fileName:指定输出日志的目的文件带全路径的文件名.
- PatternLayout:输出格式,不设置默认为:%m%n.
RollingFile 节点用来定义超过指定条件自动删除旧的创建新的 Appender.
- name:指定 Appender 的名字.
- fileName:指定输出日志的目的文件带全路径的文件名.
- PatternLayout:输出格式,不设置默认为:%m%n.
- filePattern : 指定当发生 Rolling 时,文件的转移和重命名规则.
- Policies:指定滚动日志的策略,就是什么时候进行新建日志文件输出日志.
- TimeBasedTriggeringPolicy:Policies 子节点,基于时间的滚动策略,interval 属性用来指定多久滚动一次,默认是 1
- hour。modulate=true 用来调整时间:比如现在是早上 3am,interval 是 4,那么第一次滚动是在 4am,接着是 8am,12am…而不是 7am.
- SizeBasedTriggeringPolicy:Policies 子节点,基于指定文件大小的滚动策略,size 属性用来定义每个日志文件的大小.
- DefaultRolloverStrategy:用来指定同一个文件夹下最多有几个日志文件时开始删除最旧的,创建新的(通过 max 属性)。
Loggers 节点,常见的有两种:Root 和 Logger.
Root 节点用来指定项目的根日志,如果没有单独指定 Logger,那么就会默认使用该 Root 日志输出level:日志输出级别,共有 8 个级别,按照从低到高为:All < Trace < Debug < Info < Warn < Error <
- AppenderRef:Root 的子节点,用来指定该日志输出到哪个 Appender.
- Logger 节点用来单独指定日志的形式,比如要为指定包下的 class 指定不同的日志级别等。
- level:日志输出级别,共有 8 个级别,按照从低到高为:All < Trace < Debug < Info < Warn < Error < Fatal < OFF.
- name:用来指定该 Logger 所适用的类或者类所在的包全路径,继承自 Root 节点.
AppenderRef
:Logger 的子节点,用来指定该日志输出到哪个 Appender,如果没有指定,就会默认继承自 Root.如果指定了,那么会在指定的这个 Appender 和 Root 的 Appender 中都会输出,此时我们可以设置 Logger 的 additivity=”
false”只在自定义的 Appender 中进行输出。
性能调优之日志打印的坑
一是前段时间架构组同事的一次性能优化分享,单单日志(log4j2)这一项优化性能就提升了 19 倍,QPS 从 1660 升到 32000,被震撼到了。
二是最近接手的一个项目中,日志加了彩色打印,按日志的级别设置了不同的高亮颜色,看得我眼花缭乱,用 less
等一些命令查看时还会展示出来一堆 “ESC[m]”,这让有点强迫症的我看着很不爽。
趁着技术优化,把这块也改一下,自己先爽了再说。顺便也重新认识一下在各种算法、秒杀设计大行其道的当下,这个不太起眼的小家伙。
综述
在任何系统中,日志对服务的重要性不言而喻,它是反映系统运行情况的重要依据;它轻巧、简单,与我们形影不离,使得我们在排查问题时无需绞尽脑汁。被线上服务问题毒打过的人都认可日志的重要性,但看似不起眼的日志,却是一把双刃剑,隐藏着各式各样的“坑”,如果使用不当,不仅不能助我们一臂之力,反而会成为服务“杀手”,所以,你知道有哪些场景可能导致性能问题吗?今天楼兰胡杨和各位老铁聊聊高并发系统下
Java 日志性能那些事,同时提供一套异步+随机采样方案能让程序与日志“和谐共处”。
Java 日志打印对服务的影响包括多种因素,例如日志级别、日志输出目标和日志格式等。下面的流程图展示了 Java 日志打印的一般流程和对
CPU 的影响。
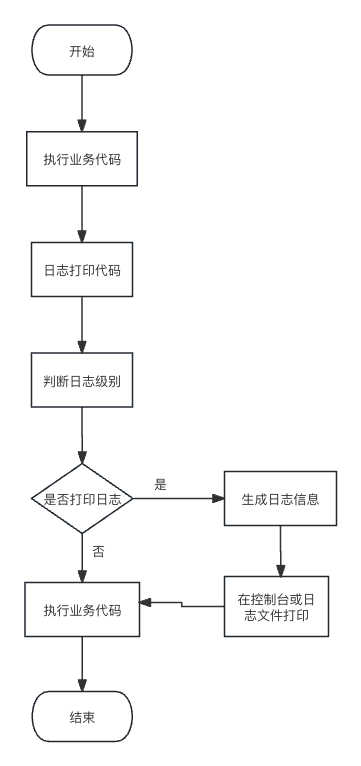
根据以上流程图可以得出以下结论:
Java 日志打印会增加代码的执行时间,因为需要执行额外的日志打印语句。
日志级别的选择会影响 CPU 的占用率。较低的日志级别(如 INFO 或 DEBUG)会导致更多的日志打印语句被执行,增加 CPU 的负担。
日志输出目标的选择也会影响 CPU 的占用率。将日志输出到控制台会导致额外的 I/O 操作,增加 CPU 的负担。
日志格式的复杂程度也会影响 CPU 的占用率。使用更复杂的日志格式可能会导致更多的字符串操作,增加 CPU 的负担。
影响性能的日志因素
位置信息
官网称作 Location Information,就是我们配置文件里的这类信息(%c{3}#%M %L),含义是当前这行日志是哪个类的哪个方法哪一行打印的。输出效果如下:
可配置的模式有很多,具体见官网 https://logging.apache.org/log4j/2.x/manual/layouts.html#Patterns 。
这里只说和位置相关的 %C or %class, %F or %file, %l or %location, %L or %line, %M or %method。
官网这几个模式的说明中也都反复强调了会影响性能。同时也给出了具体的性能数据,比常用的同步 logger 慢 1.3 ~ 5 倍。如果在异步
logger 中使用位置信息,将会慢 30 ~ 100 倍。
为什么会这么慢呢?
我们都知道,java 程序执行时,每个线程都会有自己的栈,每个方法都会生成一个 frame,要获取位置信息,就要获取当前线程的栈帧信息,java
9 之前提供了两种获取栈帧的方法
1 | |
java 9 提供了 StackWalker 类,有网友说它的性能要好一些,我没找到有力证据,看到的都是介绍跳帧的功能,有兴趣的可以深究一下。
我们就看一下 java 9 之前的 2 种方法:
有网友说 java.lang.Throwable#getStackTrace() 的性能要好一些,我也没有找到直接证据,但从调用底层 native 的方法名字看 Thread
里调用的是 dumpThreads ,看到 dump 字眼,就会联想到 stop the world ,如果真挂起线程,那效率就低了。
而且 log4j 里用的是 java.lang.Throwable#getStackTrace()。
不管是哪种方法获取堆栈信息,应该都不会太高效。
想想我们一个请求,从框架层面交给一个线程后,动辄几十层方法才能调到我们的业务代码太正常不过了。
既然这么低效,那我们不打位置信息,有问题怎么定位呢?
我仔细回想了一下过往排查问题时,好像都是通过日志内容,定位到哪一行代码,几乎没有通过类名行号去定位代码,编译后的行号准不准确也另说。
其实我们的主要目的是不通过框架获取堆栈的形式打印位置信息,我们完全可以在日志的内容中带上位置信息,通过一个切面就能搞定的事。
不同的 Appender
我们工作中一般都是把日志输出到文件中的,我们就挑 3 个文件相关的 Appender 说明一下,不同的 Appender 性能的差异主要在 I/O 上。
FileAppender 和 RollingFileAppender 内部使用的都是 BufferedOutputStream。
而 RandomAccessFileAppender 内部使用了 ByteBuffer + RandomAccessFile 技术,与 FileAppender 相比,性能提高了 20 ~ 200%。
AsyncAppender 它不能独立存在,要依赖其他的 Appenders,配置在它们之后。
它只是新起一个线程中把 LogEvents 交给了它所依赖的 Appenders。默认内部使用的是 ArrayBlockingQueue
,多线程并发打日志时,性能可能会变得更差。这种场景官方推荐使用无锁的 Asynchronous Loggers 。
Asynchronous Loggers,它是 log4j2 新提供的功能,通过新起线程执行 I/O 操作来提升性能,底层使用的是 Disruptor 框架,通过无锁线程通信,代替了
ArrayBlockingQueue 。
它支持所有 Loggers 异步处理,也支持同步、异步 组合使用。可靠性要求高的比如异常信息就可以配成同步的,其他配成异步的。
每个 Appender 的具体用法可以从官网查看,
https://logging.apache.org/log4j/2.x/manual/appenders.html
不同的刷盘策略
上面说到的 Appenders 的配置项中,都有一个 “immediateFlush”,默认 = false,日志文件不像数据库那样追求高可靠性,可以忽略此配置,知道配置为
true 性能会变差就行。
貌似所有涉及到刷盘的技术,都会提供这类的配置项,这里就不多说了。
不合理的书写方法
1 | |
如上四种写法,我相信大家或多或少都在项目代码中看到过,那么它们之间有什么区别?对性能会造成什么影响?如果此时关闭 DEBUG
级别日志,差异就显露出来了。
- 格式 1 即使它不输出日志,依然需要执行字符串拼接,属于资源浪费。
- 格式 2 缺点是需要加入额外的判断逻辑,增加了废代码,一点不优雅。
- 格式 3 缺点是仍然需要根据系统配置的日志级别判断是否打印日志,并且需要提前序列化对象为 JSON 字符串,但是,不需要拼接字符串。
- 格式 4 推荐在高并发系统中使用,优点是根据 Boolean 类型日志开关判断是否走日志打印逻辑,开关关闭时,不必校验是否需要打印日志。
Mybatis Plus 自定义日志
不常用,不写了,详见参考资料。
参考资料
启示录
富贵岂由人,时会高志须酬。
能成功于千载者,必以近察远。